

#7 | What is Gradient Accumulation ?
It's the answer to "I can't increase batch size because of limited GPU"

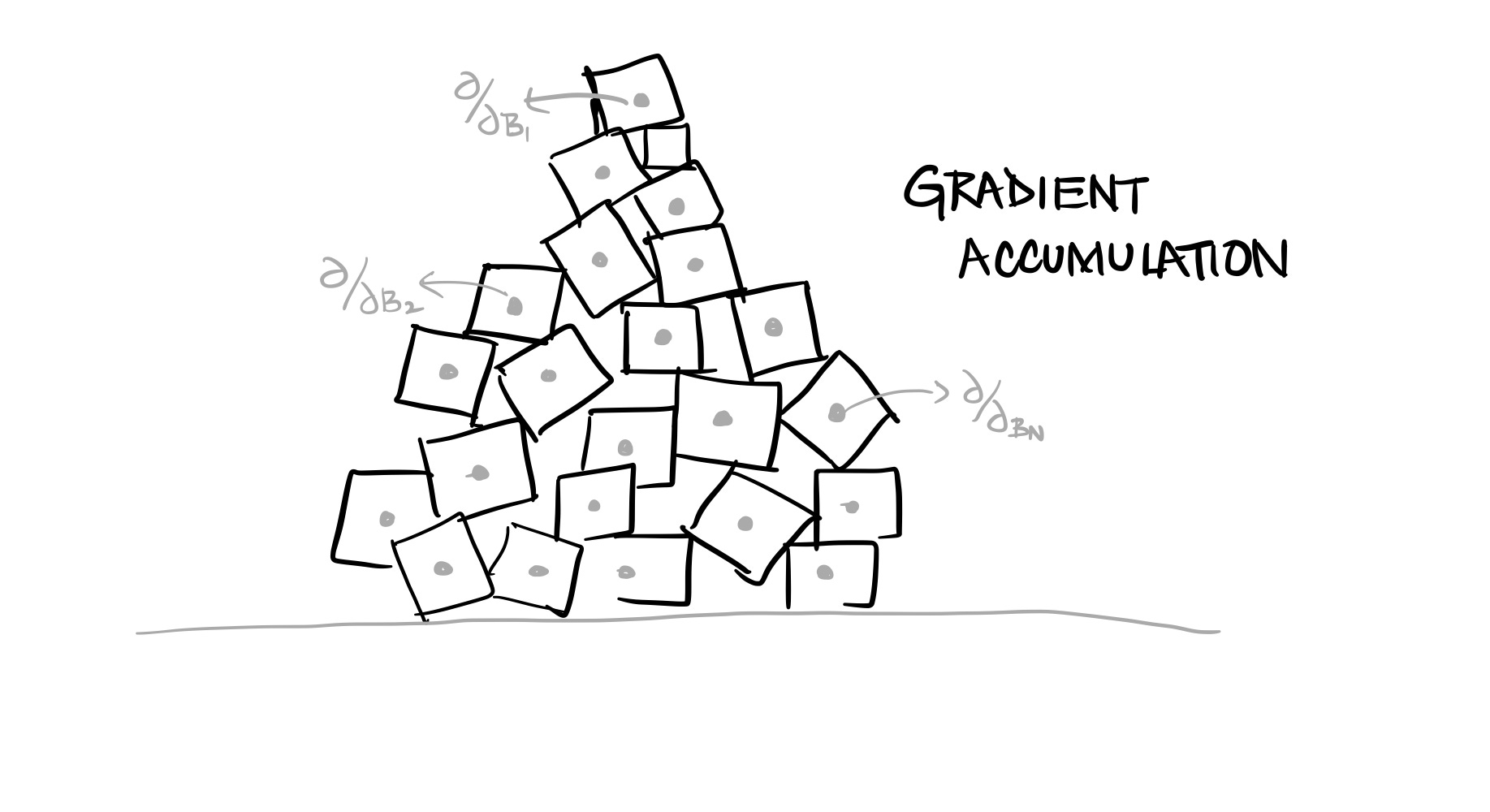
Many times while training deep neural networks, we wish we had a bigger GPU to accommodate the BIG Batch size .. but we don't !! and it leads to:
slower convergence and
lesser accuracy
Let’s revisit the typical training loop in PyTorch. We will be using this to understand Gradient Accumulation.

Let’s understand the solution and Gradient Accumulation in 3 steps:
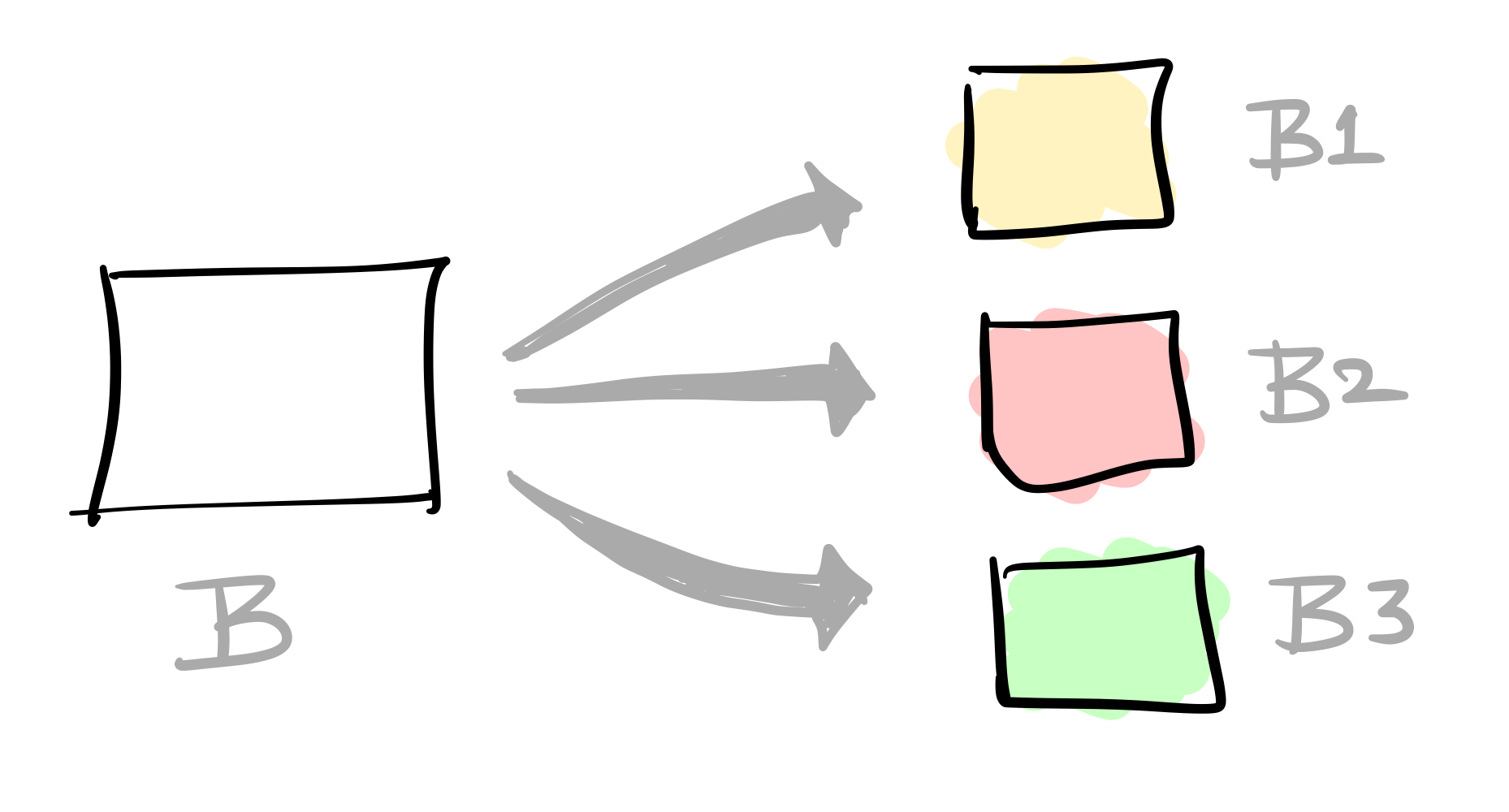
Step 1: Divide the BIG batch into smaller batches
Dividing here just means keeping the batch size small so that it fits GPU memory.
Step 2: Accumulate Gradients
This is the core step.
We can’t fit a large batch size but how about we keep track and collect gradients calculated for each batch and act on them together? The idea is to keep accumulating gradients for each of the mini-batches till we reach some number of accumulation steps.
In the below example, we are accumulating gradients for 3 steps.

How to implement this in code? Well, just don’t do “optimizer.step()” after every forward pass. And it will automatically keep on accumulating gradients for each trainable parameter.

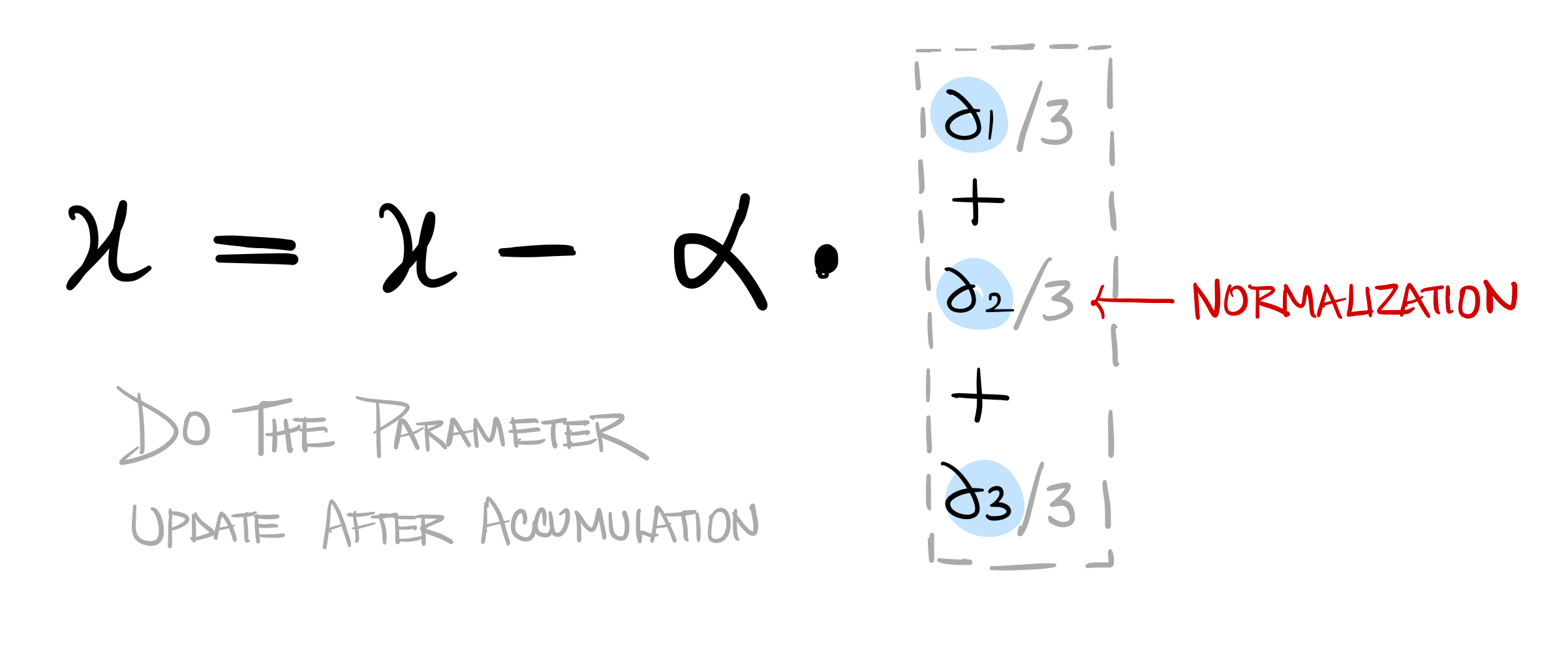
Step 3: Update parameter values using Accumulated gradients
Once we have accumulated gradients for “accumulation steps”, we go ahead and do the parameter update.

But there is a catch
Won’t the gradients be huge since we are accumulating them ?
They will be — and that’s why we need to normalize them by the Accumulation steps.

Summary :

If this post ended up in the Promotions tab, please move it to your Primary tab or Whitelist this email address, so that next time you don’t miss it.